
通过神经网络来帮助估计摄像头2D图像中描述的用户情绪
(映维网Nweon 2023年11月01日)现有的Avatar系统通常无法传达细微的面部表情或情绪状态。所以在名为“Emotion detection”的专利申请中,苹果介绍了一种通过神经网络来帮助估计摄像头2D图像中描述的用户情绪,从而优化图形建模系统的方法。
具体来说,发明使用自编码器神经网络来捕获“中性”和“表情”面部模型的latent变量表示。模型可以离线开发并存储在单个设备以供运行或实时使用。基于一的非常有限的数据样本,可以使用额外的神经网络或统计滤波器来选择性地加权第一个神经网络模型的latent变量,以提供一个逼真的中立Avatar。
所述Avatar可以与表情神经网络结合使用,并在实时操作期间由音频和/或视觉输入驱动,以生成特定个体的逼真Avatar。
在一实施例中,可以基于从表情自编码器的训练产生的数据来估计在2D图像中描述的情绪。具体而言,在训练自编码器时,获得一组具有latent向量的图像对。latent向量可以表示与表情相对应的三维特征。可以训练诸如表情CNN这样的神经网络,以从latent向量估计情绪。
所以,可以将图像输入到表情CNN中来估计latent向量,并根据latent向量的比较从图像中估计出一种或多种情绪。
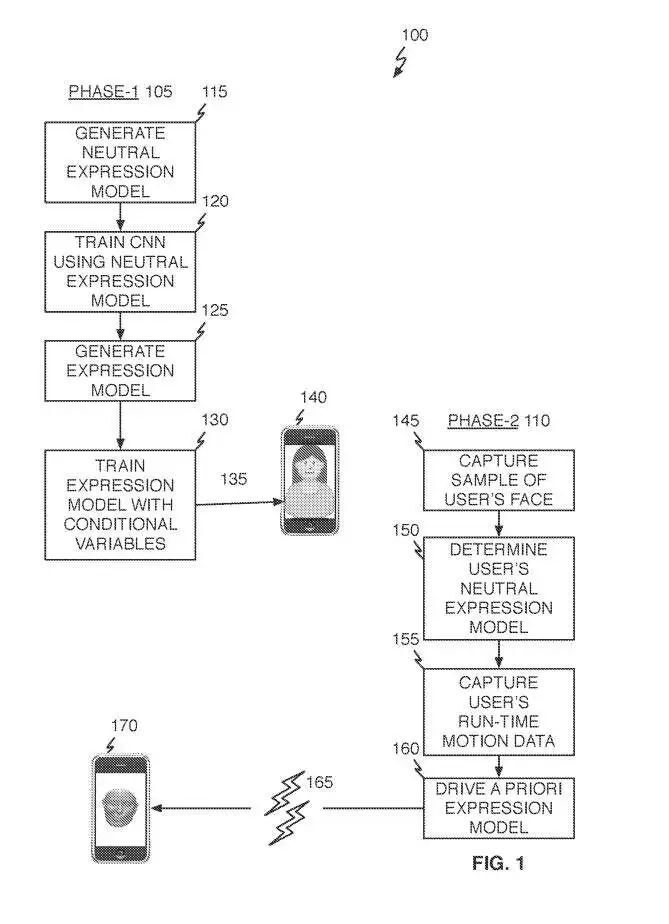
参考图1,Avatar生成操作100可以包括两个阶段。在阶段一的105,采集通用建模数据。在阶段二的110中,所述数据与有限数量的个人特定数据相结合,并用于生成代表用户的高质量Avatar。
在阶段一的105,可以从基于图像种群的中性表情模型的离线或先验生成开始。中性表情模型可能对应于处于中性姿势(即缺乏表情)的用户面部的特定几何形状。然后,可以使用115中的中性表情模型来训练卷积神经网络CNN,以便在运行时操作期间使用。
如果需要,可以将可选的条件变量应用于中性表情模型,以进一步优化模型的输出。说明性条件变量包括性别、年龄、身体质量指数等。在一个或多个实施例中,将条件变量纳入中性表情模型可以使支持模型更好地区分与诸如年龄、性别、体重指数等因素相关的面部特征。
类似的多人数据同样可用于离线或先验地训练或生成表情模型(125)。换句话说,表情模型可以指示处于表情状态的用户面部的特定几何形状。与上面类似,如果需要,可以将可选的条件变量应用于表情模型,以进一步优化模型的输出(130)。
中性表情模型、表情模型和阶段一的105操作期间生成的CNN可以存储在电子设备140。一旦以这种方式部署,当使用设备的图像捕获单元来获取特定人员(145)的相对有限数量图像时,阶段二的110可以开始。
可以将特定人的图像应用于先前训练的CNN,以获得特定用户的中性表情模型(150)。在运行时,当特定用户通过使用Avatar的应用程序与第二个人进行通信时,可以捕获特定用户的实时图像和/或音频(155),并结合个人的中性表情模型用于驱动先前开发的表情模型(160)。
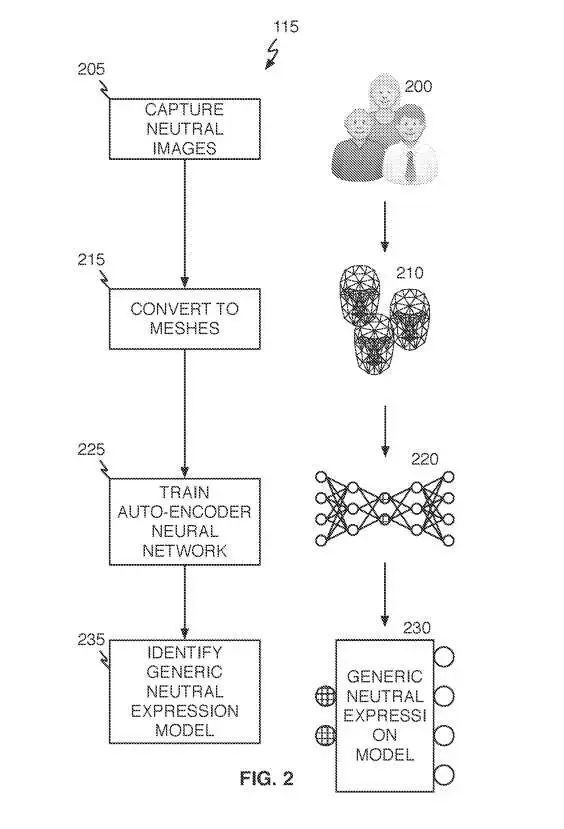
参考图2,中性表情模型生成操作115首先从相对大量的个体(205)获取中性图像200。作为说明,“中性”是指一个人具有中性表情的Avatar。例如,图像200可以通过摄影测量或立体摄影测量系统、激光扫描仪或等效捕获方法获得。每个中性表情图像200可转换为3D网格表示210(215(并用于训练自编码器神经网络220(225)。从自编码器神经网络220中,可以识别出通用中性表情模型230(235)。
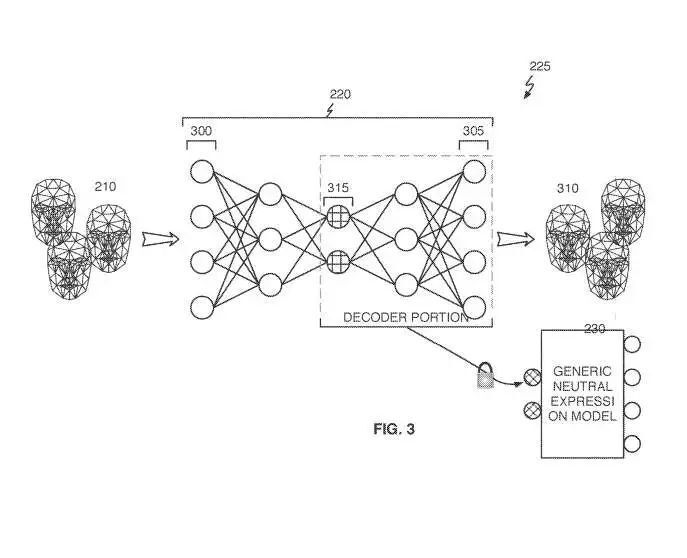
参考图3,自编码器神经网络训练操作225可以将来自中性表情3D网格210集合的每个中性表情3D网格应用于训练自编码器神经网络220,以生成输出网格310。自动编码器神经网络220可包括传统的自编码器或变分自编码器。可以训练变分自编码器,而一旦对自编码器神经网络220进行训练,可以形成通用中性表情模型230。
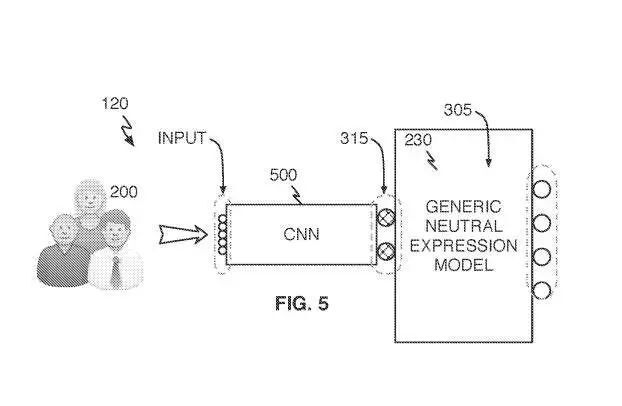
参考图5,CNN训练操作120将每个中性表情图像(应用到CNN 500的输入层。完全训练的自编码器神经网络220的输入到latent变量到输出映射数据可用于训练CNN 500。
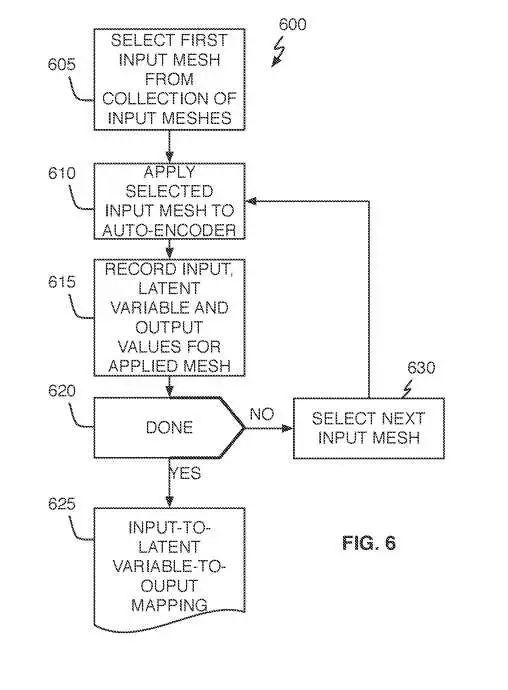
参考图6,中性表情输入到latent变量到输出映射数据采集操作600首先从输入网格210的集合中选择第一输入网格(605)。然后将所选网格应用于完全训练的自编码器神经网络220的输入层(610),以及输出层305中每个输出节点的结果输出值(615)。
如果输入网格210集合中的所有输入网格都按照610-615进行了应用,则记录的输入到latent变量到输出映射数据625完成。如果至少有一个输入网格没有按照610 – 615块应用,则可以选择下一个输入网格(630)。
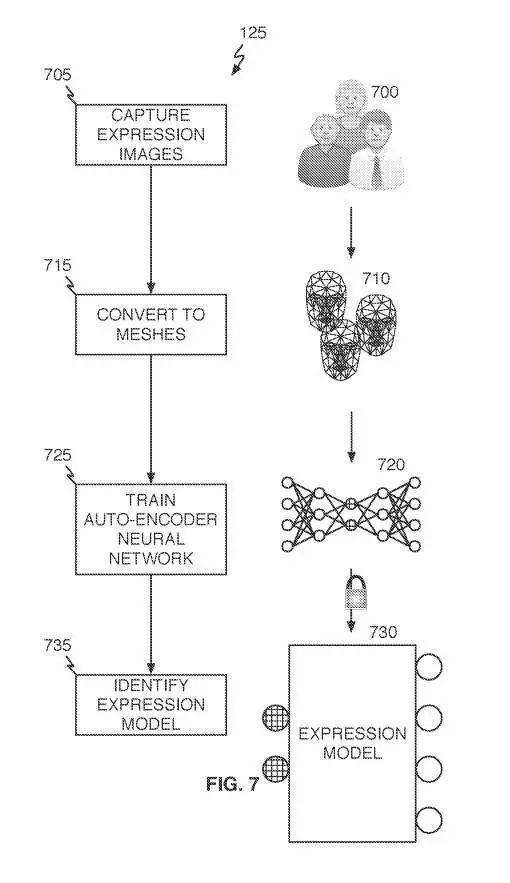
参考图7,表情模型生成操作125可以与中性表情模型生成操作115大致相同的方式进行。首先,可以获得来自相对大量个体的表情图像700(705)。图像700可通过摄影测量或立体摄影测量系统、激光扫描仪或等效捕获方法获得。每个表情图像700可转换为表情3D网格表示710(215),并用于训练另一个自编码器神经网络720(725)。从自编码器神经网络720,可以识别出表情模型730(735)。
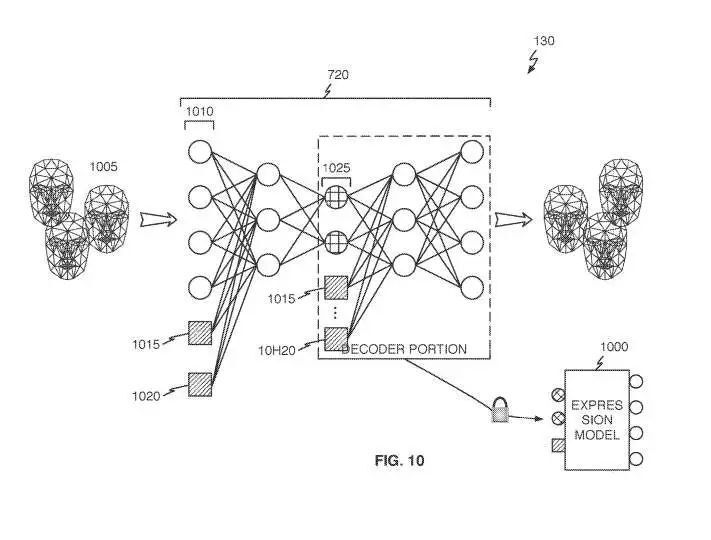
参考图10,可选条件变量可用于生成式表情模型1000,以进一步细化模型的输出(130)。为了实现这一点,可以按照图6相同方式获得对latent变量的输出映射数据的表情输入1005。然后可以识别所需的条件变量并再次用于训练自编码器720。
如图所示,表情输入1005可以结合选定的条件变量1015和1020应用于自编码器720输入层1010。选定的条件变量同样应用于选定的隐藏层1025。
然而,模型中遗漏的人脸细微动作可能会减损生成的Avatar真实感。为了将细微动作合并到上述模型,可以使用特定方面的网格来训练如上所述的自编码器神经网络。
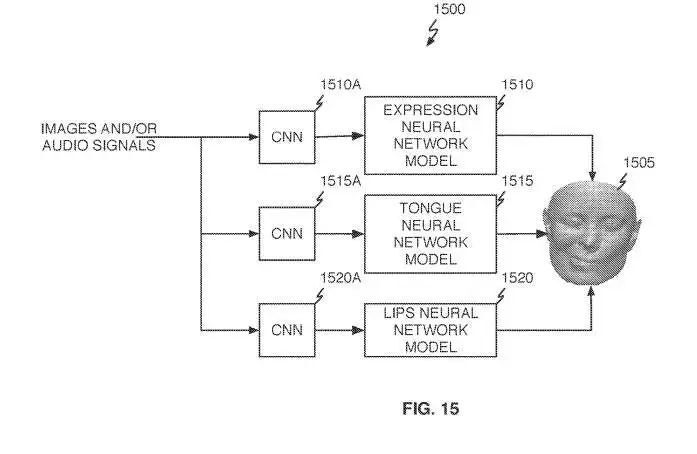
如图15所示,Avatar系统1500通过三个独立的模型路径驱动Avatar 1505:表情神经网络模型1510;舌头神经网络模型1515;嘴唇神经网络模型1520。
对于音频驱动的CNN,如果使用音频信号作为输入,系统将能够很好地预测嘴唇和舌头的运动,但无法预测面部表情、面部情绪或眨眼。换句话说,音频驱动的CNN会对语音的唇形动作有很强的判断,但对其他面部动作的判断较弱或不准确。
基于视频的CNN则对一般的面部表情和眼睑运动有较强的判断,但对嘴唇和舌头运动的判断较弱,特别是当使用的摄像头无法清楚地看到嘴唇和舌头时。
将两组输入与每个latent变量的适当权重相结合,可以给出比使用单独CNN更好的预测集。
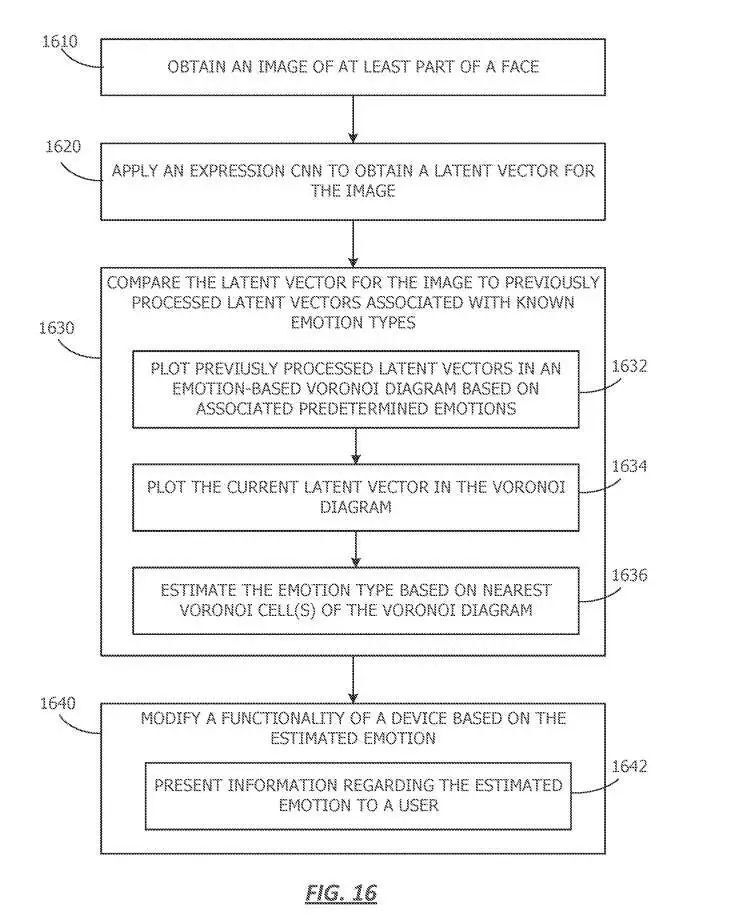
图16描述了用于从图像估计情感的操作。从1600开始,获取至少一部分人脸的图像。
在1620,电子设备应用表情CNN来获得图像的latent向量。表情CNN可以通过使用一组成对的数据来训练,其中每对数据包括一个图像和对应于图像的latent向量。由于所述自编码器进行了训练,所述自编码器可协助从3D形状获得latent表示。
在1630,电子设备将图像的latent向量与先前处理过的与已知情绪类型相关的latent向量进行比较。例如,可以通过将图像的latent向量与先前处理的latent向量和相关情绪进行比较,从而估计图像的一个或多个情绪,以找到一个或多个最接近的匹配。
任选地,将图像的latent向量与先前处理过的latent向量进行比较,在1632,可以包括基于相关预定动作的基于情感的Voronoi Diagram中先前处理过的latent向量。例如,在一个或多个实施例中,先前处理的图像可以是训练表情CNN的图像。
基于相似的特征对图像向量进行聚类,使得具有相似latent向量的图像彼此靠近。在一个或多个实施例中,由于latent向量是基于表情,具有相似表达的图像将聚类在一起,并且具有相似特征的情绪簇可以彼此靠近绘制。
Voronoi Diagram可能包括Voronoi Cell,每个Cell可能与一种情绪相关联。在1634,当前图像与先前处理的latent向量绘制。可以基于与所述图像关联的latent向量绘制所述当前图像。将当前的latent向量与绘制的latent向量进行比较,以确定最接近的匹配。
然后在1636,电子设备根据最近的Voronoi Cell或来估计情感。例如,当前latent向量可能与具有“快乐”标识的latent向量最相似。因此,当前图像的估计情绪可能是“快乐”。在一个或多个实施例中,图像可以与基于最佳匹配的多个估计情感相关联。
在1640,电子设备根据估计的情绪修改设备的功能。估计情感的电子设备可以指导不同设备的修改功能。例如,所述功能可以与计算机生成现实应用相关,亦即XR。例如,如果VR用户在看到内容时感到高兴,则系统可以会显示更多类似的内容。如果XR用户感到生气,则系统可以显示不同的内容。
在1642,电子设备可以向用户呈现有关估计情感的信息。
相关专利:Apple Patent | Emotion detection
https://patent.nweon.com/31095
名为“Emotion detection”的苹果专利申请最初在2023年6月提交,并在日前由美国专利商标局公布。



